Deep neural networks (DNNs) have revolutionized machine learning by showing a remarkable performance in extracting and representing high-level abstractions in complex data. DNNs are stacks of multiple layers of neurons, used to solve complex tasks such as image classification and recognition. Due to their excellent performance in different tasks, they have been adopted in mobile and edge devices requiring power/energy-efficient mobile and embedded architectures to execute DNNs. Moreover, edge devices are based on a variety of hardware platforms and networks that change dynamically over time. To meet the demands of heterogeneity and dynamic changes within the edge devices framework, the execution time is of paramount importance. While DNNs have been proven very effective in said tasks, their hardware implementations still suffer from high memory and power/energy consumption, due to the complexity and size of their models. Therefore, research efforts have been conducted towards more efficient implementations of DNNs.
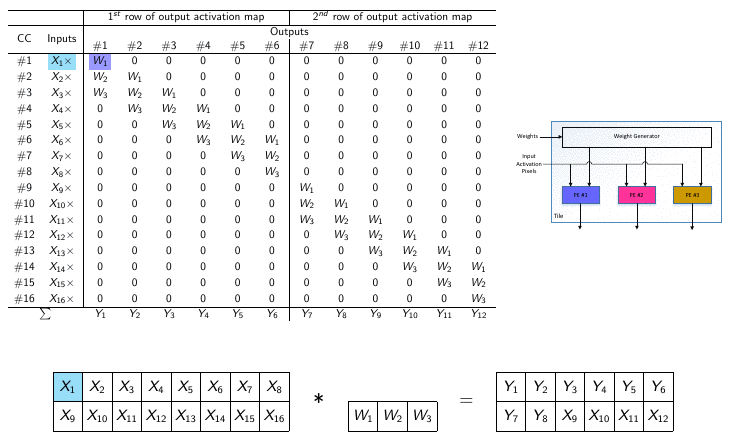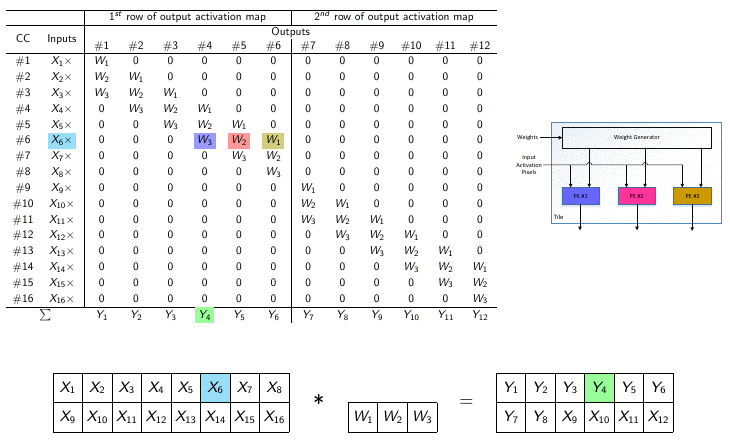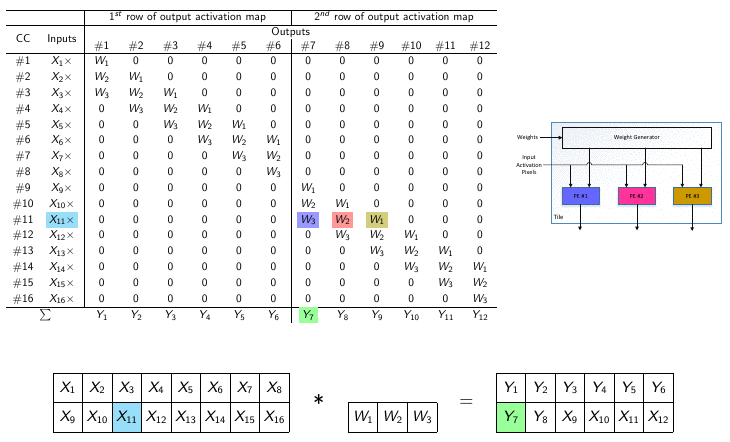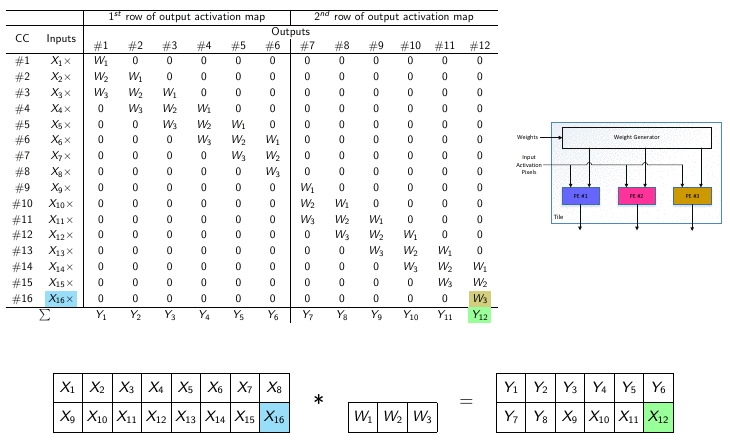
The parallel nature of DNNs has led to the use of graphical processing units (GPUs) to execute neural networks tasks in the past decade. Although classification task is not problematic when running on mainstream processors or power-hungry GPUs, edge applications have much tighter power budgets of mW-level. Therefore, application-specific integrated circuits (ASICs) have been proposed as alternatives to GPUs for hardware implementations of DNNs, since custom hardware consumes less power and results in lower latency compared to GPUs and CPUs. However, even using custom hardware results in significant power consumption, mostly due to accesses to off-chip memory. In this lab, we explore different hardware/software solutions to reduce computational complexity of DNNs. More precisely, we explore pruning and quantization methods to reduce the computational complexity on the software side. On the hardware side, we investigate new platforms (i.e., dataflows and architectures) enabling the best trade-off between flexibility, scalability, computing power and energy consumption.
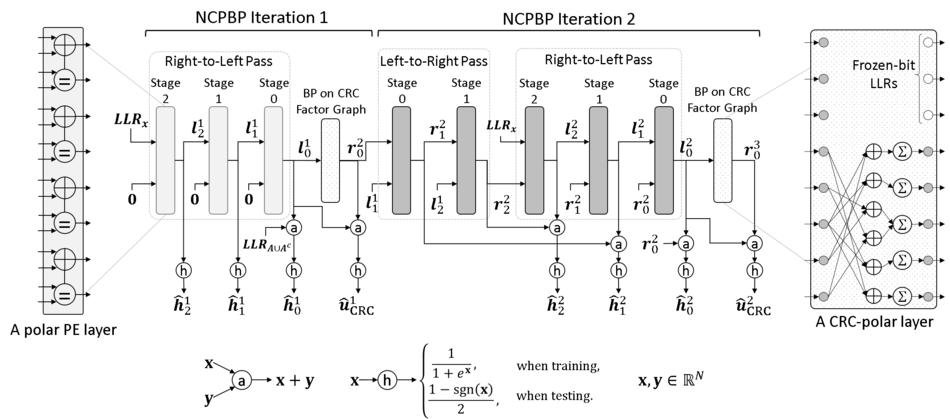
In ISIP, we also adapt deep learning techniques to solve conventional problems on channel coding and communications in general. Our current work in this matter is to optimize belief propagation decoding of linear block codes by using a set of trainable correcting parameters. The correcting parameters help the conventional belief propagation decoding to overcome the detrimental effects of erroneous messages caused by short cycles and inaccurate approximation of the hardware friendly min-sum decoder.
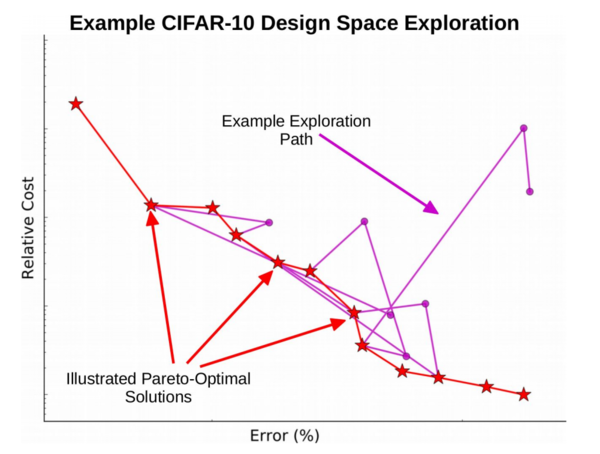
Neural networks are difficult to design due to the large number of hyper-parameters involved in their architecture. OPAL is a tool that automates and facilitates the design process for neural networks. It uses a meta-neural network to perform response surface modeling and to predict costs and accuracies for any given architecture input. OPAL then provides the user with the network architectures it found that have the best cost to accuracy trade-off, so the user can determine which network best suits the criteria they have in mind.
At present, OPAL optimizes multi-layer perceptron (MLP) and convolutional neural network (CNN) accuracy and cost by manipulating: a large variety of network hyper-parameters, including but not limited to depth of convolutional and fully-connected layers, numbers of filters/neurons per layer, types of activation functions, amount of dropout applied, dimensions and strides of convolutional filters, etc. The framework was made to be extensible and can be applied for designing neural network architectures for classification and regression problems with arbitrary datasets. To accelerate training and evaluation, OPAL automatically generates CUDA code for GPGPU execution.